posted by yuksickening at
8:22 PM
|
0 comments
![]()
![]()
Friday, December 01, 2006
Tuesday, October 24, 2006
It has been 14 days since I last updated my blogs. Time sure flies. My schedule was filling with huge amount works and lots of problems on the performance sides of the system. I stopped implementing new requests, passed my tasks to my juniors, and concentrated more on improving the performance of our previous implementation.
We launched 3 sites of our .NET system. For the first week, everything went fine except for the odds information display trouble. The second week of launching, we started running into problems. Everything also started with the odds information display. Our odds cache wasn't stable. In order to relieve the load to the web server and the system itself we implemented a middle layer with .NET Web Services to obtain the odds information. We implemented it in the way that there was a infinite polling mechanism to get the information from the database and kept that information always fresh in the cache of the Web Services. For our problems, our polling mechanism always stopped unexpectedly. Before launching the new 3 sites, I worked around this problem by stopping the IIS to recycle its worker process on IIS schedule. This idea worked fine when we had less sites and the more sites we had problem started showing. The complains that we got from the customer more and more as my 3 sites stayed in the production. I listed down 3 things, I had to solve immediately.
- Odds Cache -> use .NET Cache Object because it has the automatically expiration parameters for each objects stored in there.
- Improve the display speed of odds information.
- Check up our server. It starts to respond really slow on some requests
I tried to improve the odds display first. The solution for this was so much easier than I thought, I just changed the way of calling a function which is used to create our betting slip. Something could surprise people that it had an impact on the rendering engine of Internet Explorer 6.
<span onclick="parent.frameA.buildSlip()">0.98</span>
to
<span onclick="a();">0.98</span>
<script type="text/javascript">
function a() { parent.frameA.buildSlip();}
</script>
<script type="text/javascript">
function a() { parent.frameA.buildSlip();}
</script>
It was not just out of no where I made this changes. I went to read some articles about IE having some memory leak issues in its javascript engine. And the part of circular references of register onclick event caught my attention.
I changed the odds cache to the new way using the Cache Object, and did more tunning on our display scripts for my last chance before the management's orders to switch 2 of our sites back to the good old ASP version. My tests showed positive results, deployed new changes to the production was the last thing I did before leaving the office.
On our critical night, our web server drive was filled up with logs files from IIS. I forgot to turn off the logs file. Next morning, my email was full of complains from the operators. :( They should've called me ... As promised with the management, we switched back 2 sites to our old versions.
... and to be continued ...
posted by yuksickening at
11:18 PM
|
0 comments
![]()
![]()
Tuesday, October 10, 2006
Another week started with a lots of goals to achieve. Our first iteration of the new implementation of our Admin 1 system will conclude at the end of this week. My part hasn't done yet. I'm behind my own schedule.
Last week, our external consultant brought in a specialist who was from Taiwan to help us on improving our system. The specialist was introduced as Microsoft Product expert. However, the first impression we had for him was totally opposite. He introduced COM+ to us, a technology which Microsoft is replacing with .NET. The whole week, we spent our time in those COM+ meetings. The really good thing he tried to implement for us a COM+ server to try instead of telling us to implement what we didn't want to do.
We tried the COM+ servers over the weekend. Coincidently, the last weekend all the major leagues were off for the EURO 2008 qualification rounds. The load of the system won't be so high. My supervisor took one of our largest sites to test how the COM+ performed. The site was slower than one without COM+. It was obvious that things's slow down because now a request from a web server had to go through COM+ server to get the objects and after than came back to the COM+ server to execute the request. COM+ server introduced an intermediate step to connect to the database. Personally, I think this is one of the reasons for Microsoft to drop the COM and COM+ technology by .NET. ADO.NET layers provides the same thing what the COM+ does in term of reducing the number of connections from the web servers to the database servers with a pool of SQL connections. I also think our specialist knows this, and I hope that too.
Advanced Betting System from London came to our company in the middle of the week to introduce their betting software for bookies. First time, we got to attend these demo like this. It was a really well-organized system, and using service oriented software platform. They didn't use XML as the data transportation, but another Servlet thin layer instead to reduce the amount of data to transfer over the network. This is exactly what we want our software to be like in the future. My colleague was talking about this couple months ago and we are trying to design our Admin 1 system in the way that later on we could switch our system into services oriented software platform in the easiest way. My colleague is really good at visioning and look for the future development of our software. His Master degree in Computing Science shows its true values.
Saturday night was really peaceful for us. The load to the database wasn't high. There were no major problems except some little bugs on the interface of our .NET member sites. We had launched 3 more small sites and the .NET system is increasing its portion in our system.
... Sunday, our off day ...
posted by yuksickening at
11:59 AM
|
2 comments
![]()
![]()
Sunday, October 01, 2006
Being too confident has become a bad characteristic for us. Our headaches - our DB performance problems - came back. Our database was jammed again this Saturday.
Last week, we worked hard to get most the load of main database out to replication. Going to this Saturday, we were pretty confident that there would be a smooth night. 9PM peak time came with more than 40 live matches ranged from all the soccer leagues around the world. As usual, all the performance graphs and SQL Server profilers were turned on. This time I have learnt how to set up a profiler for myself. I also need to monitor the Admin 2, yesterday I continued to move out some pages to access the replication instead of the main Database. Everything was running smoothly. The main DB CPU usage was only around 10%. We started to relax a little.
There were some couple problems with our ASP sites. My supervisor changed the way we stored our odds change time. His display odds javascript didn't run correctly anymore. Problems were soon gone away, since he is my supervisor ... hehe i'm good he must be better ... jeese starting to be cocky ... (I should look at my first sentence again *winks*)
Since all the servers were running nicely. I went to fix bugs in our .NET member sites and ready for the launch of 9 more sites in the futures. All the sites must pass the acceptance tests. We failed 3 times already; however, the errors were not from our codes, it was just that we didn't have the correct data and enough data for the testing. The data we copied from the data warehouse into our development environment wasn't enough. I decided to deploy the rest of 9 sites into real production environment for a final testing.
11PM, the peak time almost passed and the load became less. Everything was running smoothly. My colleague left work. I still had some deployment on the way, and I decided to stay a little late. At the time I looked at the performance graph for my usual check. Something unexpected happened. The performance graph showed unusual behaviours. Database was jammed again. I looked over to my supervisor, and we started receiving complains.
... SETTLEMENT again ...
The operation did the calculation for the win/loss after the matches were over. This is called settlement process. And the database was jammed when the settlement code was executing. The problem was why it didn't happen when my supervisor executed the settlement himself. How to solve this? What could we do now? We are running out of options.
... I was off on Sunday ... but still kept monitoring the system from my house ... next week, we will have to continue to look into this issue again.
Database is not my specialty ... the only thing I know is to listen to my colleague and my supervisor ... well I will learn ...
This Saturday, our external consultant also invited a SQL specialist who was from Taiwan to help us to improve the database performance. He introduced us to COM+ ... a technology which Microsoft is replacing with .NET Remoting and Web services. The first impression from us wasn't too good for him. Let's see what he will have for us.
posted by yuksickening at
11:54 PM
|
0 comments
![]()
![]()
Thursday, September 28, 2006
Adapt to "constant" changes
Technology is changing every day, we have to update ourselves constantly to keep up with the pace. In 2002, our software was implemented with ASP and SQL 2000 and now we are replacing the old software with ASP.NET 2.0 and SQL 2005. Next year, we may change to something else ... who knows ... It is not only just the technology changes but also customers' requirements also change day by day. Today the requirement will be a square; but tomorrow, the square may turn into an oval. The businesses are changing, the requirements must be changed as well. To cope with new demands, new technology will be employed, and new ways of doing things will be used. Putting everything together creates a cirle. That cirle creates an indefinitely flow for those who choose to be in this technology industry.
Last night, I brought up new features to our Admin 2 website as well. I also found couple of bugs, bugs in the new features and also bugs in one of the old features.
- Special character in the team name, my javascript will return an error when this team name occurs
- Back functions of the live delete trace is not working
These were rare errors that's why our operators could not pick them up.
Today we start implementing the Company Admin website after a series of delay due to something called "PROCESS". The management wanted "PROCESS" and "PROCESS" reduced the productivities. "PROCESS" is necessary for any development firm; however, implementing it could not be done in a sort period of time. I have learnt a lots out of this process improvement period. For our company, heavy-weight process like CMMI is too much because our development team is pretty small. Light-weight process like Agile Development is more suitable to start with.
... first iteration is on the way ...
posted by yuksickening at
11:33 PM
|
0 comments
![]()
![]()
Monday, September 25, 2006
Weekends has become our days for tuning and monitoring for the performance of the whole system. Our database performance issues is always on top our our lists. Last weekends wasn't an exception. We had done through a series of changes to improve our system. Costs and expensive lessons always accompanied with those changes. Expensive lessons were learnt, costs was paid under the expense of 3 hours downtime of our system on one of the most busy day of our business.
Saturday
Last week we implemented hardware load balancing. The load balancing worked like a charm. The hardware sent additional cookies in the URL and the response sent back to the firewall, based on the cookies it will send the requests to the correct server. Couple months back, we tried this method and we failed. Now with new hardware, it works so good. I won't have to do the software load balancing anymore for our Agent system.
Our night started with unusual behaviours of our servers which were detected from the graph of Window Performance Tools. At the moment, we have 2 servers for the Agent System. We deployed our Admin 2 on our Agent Server #1. This enabled us to have an idea about how our main database performed.

Explanation: The top window in the picture was the monitoring graph of our Agent Server #1, the underneath window was the the monitoring graph of Agent Server #2. The second graph showed the normal activities of a server. Red Line: CPU usage of the server; Blue Line: request executing in the CPU; Yellow Line: requests comming to the server per second. The first graph indicated that the database was being locked, and our website became slow on the customers' sides. The request executing ran high that meant there were request comming and some of them had to wait for the database to timeout. Time to do something to the database to release all the locks.
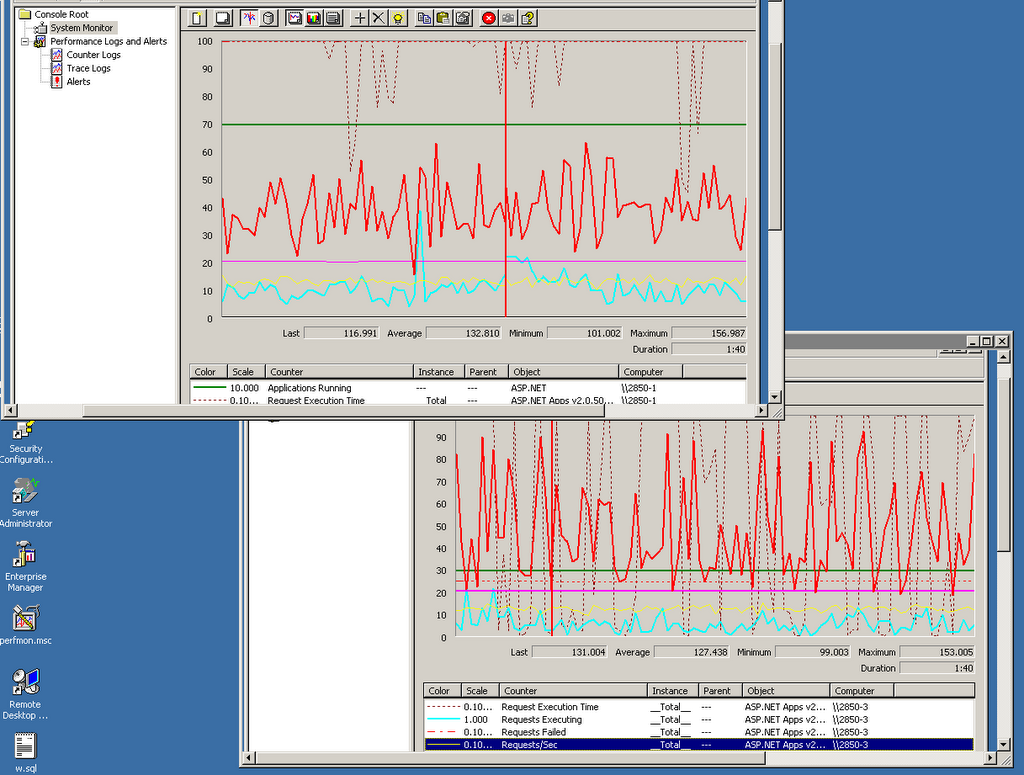
Explanation: This picture showed the normal activities of both Agent Servers.
The main CPU database remained at around 30%, but we still received complains from our operation that our web admin site was slow, and the Admin 2 as well. Database was jammed again? My supervisor then killed the physical connection which led to our main database. The situation became better. We learnt one more thing. When the database CPU is low, it doesn't mean that the system will perform normally. Even though the CPU is low, the database is still locked at somewhere.
My colleague added more counters into the Window Performance Tools to monitor the "lock requests" and "lock waits" for the database. After a while of monitoring, we found what we wanted. Before the database was jammed, the "lock waits" counter jumped higher, and so did the "lock request". At the same time, the performance tools on our Agent Web Servers also showed "Request Executing" Counter getting higher. My supervisor had to kill the physical network connection again in order for our database solved all the current locks.
We continued to monitor some more again. There were still lots of reading in our main database
- balance of our agency system
- bet list of nearly 40,000 customers
- reports of our admin 2
- total bets, and forecast in our company admin
"We will move all those read out of our main database." That was the conclusion for that we had for the night. I was in charged of changing the code of the agent system, and we encountered a big issue. Our current source code inside the repository was the ongoing development code. I could not fix on that source code. I had to rip out the production source, created a new project and made my amendments in there. Big room for errors was awaiting me.
Hardware issues sometimes also had affects on the performance? Our external consultant thought the hyper thread functionalities might create the performance issue as well. The external consultant also decided to turn the hyper thread feature off on the next reboot time of the system.
Sunday
Another weekend I had to come to work, and my supervisor has worked like this for the past 2 years to maintain the system up and running. I guess I'm starting following him. Well, it is the nature of our jobs as programmers.
I had 2 jobs to finish
- remove all report store procedures call from our admin 2 to replication database
- bring master agent list to replication and put some delays for the customers to see the new updates from replication
I finished the first task weekly. I grabbed my colleague junior to test my new changes while I proceeded the next task. I guessed he was being unlucky when he let me see him online on his off day. The test was fast, and everything was working fine. I deployed new version for our admin 2 quickly. Everything proceeded so smooth, and I should be out of the office pretty soon I thought.
Yesterday, before I left, I already set up the new project for our agent code in order to implement new codes without bringing our ongoing development into our development servers. I already tested the codes in our development environment. Everything rans smoothly. After getting signal from my supervisor, another version of agent systems were deployed again in our servers. I made a test site to test our new codes. I got errors, totally could not log in. There were strange errors. Parameter could not be null. Parameter value: value! What was the h*** going on? In the development system, everything was working fine. I had to revert on our old code back, and tried debugging the codes. After a while, I found out our new codes for new functionalities was causing problem. I passed in a null value into the String.IndexOf function of .NET . It was totally going off my mind when I saw the error message like that for that kind of mistake which was thrown out by the .NET Framework.
Database was restarted. Anxiously to wait for the main DB to be up again, strange things happened. In the performance windows, the CPU of the main DB quickly raised up to 100%. Our supervisors killed the LAN connection to the main DB again. After he killed the connection, the power in his house went out and it was time for him to come to the airport to catch the plane to Manila. No one turned the LAN connection back on. I had to call our external consultant to turn the connection back on. There were no remote connection for me to go in anymore. When the DB was back on, the CPU raised up to 100% again. We thought that it'd be the hyper thread function turned off causing the problem. Main DB was shut down again and restarted.
Our external consultant monitored the SQL profiler and told me everything single SP call from the agent system was going to the main DB instead of going replication servers. I moved the old codes back immediately and I grabbed my colleague to monitor for me and I went to figure out what went wrong. There were 2 things I picked up.
- My junior changed my default setting inside one of the main components of our agent software packages.
- The default connection to the main DB wasn't changed, it must be changed.
This was totally my mistake. I should've checked more carefully. Expensive lessons for me, I should've been more careful, and replaced the code one by one from the least access sites to the more access sites and always monitored the SQL profiler along the way. I underestimated the changes I did. The system I built and I still made mistakes. After fixing all the bugs, I learnt this time, and replaced the agents website one by one and monitored closely the profiler which my colleagues had set up for me.
After 3 hours downtime and unstable performance, our system was back on again. At the same time, my supervisor was doing the peformance improving implementation as well, he moved all the report from our member sites to replication. I decided to stay at work through the peak time to monitor a bit more closely, and to make sure everything running normally. Our system performed extremely good, no more jams for the night. Our agent servers didn't show anything unsual anymore. The main DB CPU was under 15% for the whole time. Next week, we will have to monitor again. Hopefully everything solved.
It was a long weekend ... going home and looking for my bed ... that was the only things left in my brain when I left work ...
posted by yuksickening at
3:11 PM
|
2 comments
![]()
![]()
Tuesday, September 19, 2006
We have solved a lots of requests last week. Today, I have free time again to update this blog with the actions of last weekend. It was totally a busy weekend.
I finished implementing the reducing bandwidth for our member sites. The implementation wasn't to the point that I wanted it to be but it was alright, simple version first and more complicated version will come later. In comparison to the ASP version, our version reduces probably 15% more of the data transfer to the clients' browsers.
Last Saturday was a really chaotic day. We encountered with so many unknown problems. We kept receiving complains from our operations about the site being slows, and we experienced the lagness ourselves too. The network was really smooth, the ping plotter program didn't show any disruption. The CPU usage of the database was at 30%. Everything seemed normal except the sites were slow. The situation continued getting worse, the trading general dispute director also came to our IT department to check what went wrong; our big bosses were all present. Eventually we pinpointed the problem which probably was the upgrade of 2 RAMSAN units. We did upgraded them to double the units capacity on Thursday. Our supervisor tried to change the log of SQL server to different RAMSAN unit. The situation seemed better a little bit; however, there were still complains.
In technical term, our business is database-centric. Like an MMORPG game, the business relies extensively on the database performance with concurrently log in of more than 38000 users at peak time. Our database has problems; as a result, our business also suffers.
A half an hour later, we used the window performance monitoring system to monitor the write and read disk queue of those RAMSAN units. Everything was normal again. Strange, there was no big changes. At the time of the problem, we did a serial of changes to the disk; it didn't help. Then how everything became normal ?. The load to the database remained the same, even a bit more than half an hour ago. STRANGE !!! We had so many factors to consider in order to pinpoint the problem exactly.
Our Agent web server got problem as well. It reached the its capacity limits. Its CPU usuage was always at 97-99% at peak time. "On Sunday, we will try hardware load balancing from the F5 for the Agent system" my supervisor said to me. I went to set up the server for him to prepare for Sunday.
Saturday night became a long night for us. Database performance still remains our biggest issues.
Sunday night, with just a bit less load than Saturday, the system performed smoothly. Was it our external consultant's assumption correct? We didn't know, and could not claim what he found to be correct problems that we had on Saturday, too many factors to concern. He told me in the afternoon that he found the problems; the problems maybe came from those unused indecies which we left in the main table. He removed it out.
When it came to the settlement part, we still have big problems even though we were using our new codes for the settlement; we did test it thoroughly and it was running much faster than the older versions.
We succeeded with the load balancing from our F5 firewall with one of our site. That was the only good news for us for the whole weekend.
... definitely have to monitor again on the coming weekend ...
posted by yuksickening at
2:21 PM
|
0 comments
![]()
![]()
