Weekends has become our days for tuning and monitoring for the performance of the whole system. Our database performance issues is always on top our our lists. Last weekends wasn't an exception. We had done through a series of changes to improve our system. Costs and expensive lessons always accompanied with those changes. Expensive lessons were learnt, costs was paid under the expense of 3 hours downtime of our system on one of the most busy day of our business.
Last week we implemented hardware load balancing. The load balancing worked like a charm. The hardware sent additional cookies in the URL and the response sent back to the firewall, based on the cookies it will send the requests to the correct server. Couple months back, we tried this method and we failed. Now with new hardware, it works so good. I won't have to do the software load balancing anymore for our Agent system.
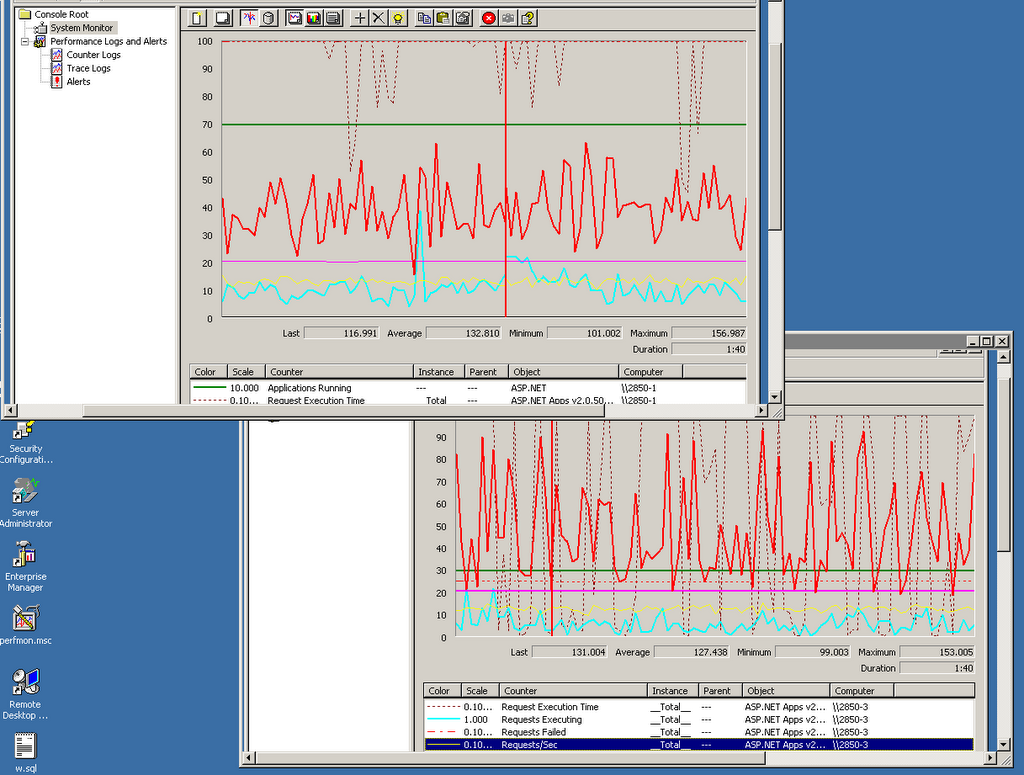
Our night started with unusual behaviours of our servers which were detected from the graph of Window Performance Tools. At the moment, we have 2 servers for the Agent System. We deployed our Admin 2 on our Agent Server #1. This enabled us to have an idea about how our main database performed.
 Explanation
Explanation: The top window in the picture was the monitoring graph of our Agent Server #1, the underneath window was the the monitoring graph of Agent Server #2. The second graph showed the normal activities of a server.
Red Line: CPU usage of the server;
Blue Line: request executing in the CPU;
Yellow Line: requests comming to the server per second. The first graph indicated that the database was being locked, and our website became slow on the customers' sides. The request executing ran high that meant there were request comming and some of them had to wait for the database to timeout. Time to do something to the database to release all the locks.
 Explanation:
Explanation: This picture showed the normal activities of both Agent Servers.
The main CPU database remained at around 30%, but we still received complains from our operation that our web admin site was slow, and the Admin 2 as well. Database was jammed again? My supervisor then killed the physical connection which led to our main database. The situation became better. We learnt one more thing. When the database CPU is low, it doesn't mean that the system will perform normally. Even though the CPU is low, the database is still locked at somewhere.
My colleague added more counters into the Window Performance Tools to monitor the "lock requests" and "lock waits" for the database. After a while of monitoring, we found what we wanted. Before the database was jammed, the "lock waits" counter jumped higher, and so did the "lock request". At the same time, the performance tools on our Agent Web Servers also showed "Request Executing" Counter getting higher. My supervisor had to kill the physical network connection again in order for our database solved all the current locks.
We continued to monitor some more again. There were still lots of reading in our main database
- balance of our agency system
- bet list of nearly 40,000 customers
- reports of our admin 2
- total bets, and forecast in our company admin
"We will move all those read out of our main database." That was the conclusion for that we had for the night. I was in charged of changing the code of the agent system, and we encountered a big issue. Our current source code inside the repository was the ongoing development code. I could not fix on that source code. I had to rip out the production source, created a new project and made my amendments in there. Big room for errors was awaiting me.
Hardware issues sometimes also had affects on the performance? Our external consultant thought the hyper thread functionalities might create the performance issue as well. The external consultant also decided to turn the hyper thread feature off on the next reboot time of the system.
Another weekend I had to come to work, and my supervisor has worked like this for the past 2 years to maintain the system up and running. I guess I'm starting following him. Well, it is the nature of our jobs as programmers.
I had 2 jobs to finish
- remove all report store procedures call from our admin 2 to replication database
- bring master agent list to replication and put some delays for the customers to see the new updates from replication
I finished the first task weekly. I grabbed my colleague junior to test my new changes while I proceeded the next task. I guessed he was being unlucky when he let me see him online on his off day. The test was fast, and everything was working fine. I deployed new version for our admin 2 quickly. Everything proceeded so smooth, and I should be out of the office pretty soon I thought.
Yesterday, before I left, I already set up the new project for our agent code in order to implement new codes without bringing our ongoing development into our development servers. I already tested the codes in our development environment. Everything rans smoothly. After getting signal from my supervisor, another version of agent systems were deployed again in our servers. I made a test site to test our new codes. I got errors, totally could not log in. There were strange errors.
Parameter could not be null. Parameter value: value! What was the h*** going on? In the development system, everything was working fine. I had to revert on our old code back, and tried debugging the codes. After a while, I found out our new codes for new functionalities was causing problem. I passed in a null value into the String.IndexOf function of .NET . It was totally going off my mind when I saw the error message like that for that kind of mistake which was thrown out by the .NET Framework.
Database was restarted. Anxiously to wait for the main DB to be up again, strange things happened. In the performance windows, the CPU of the main DB quickly raised up to 100%. Our supervisors killed the LAN connection to the main DB again. After he killed the connection, the power in his house went out and it was time for him to come to the airport to catch the plane to Manila. No one turned the LAN connection back on. I had to call our external consultant to turn the connection back on. There were no remote connection for me to go in anymore. When the DB was back on, the CPU raised up to 100% again. We thought that it'd be the hyper thread function turned off causing the problem. Main DB was shut down again and restarted.
Our external consultant monitored the SQL profiler and told me everything single SP call from the agent system was going to the main DB instead of going replication servers. I moved the old codes back immediately and I grabbed my colleague to monitor for me and I went to figure out what went wrong. There were 2 things I picked up.
- My junior changed my default setting inside one of the main components of our agent software packages.
- The default connection to the main DB wasn't changed, it must be changed.
This was totally my mistake. I should've checked more carefully. Expensive lessons for me, I should've been more careful, and replaced the code one by one from the least access sites to the more access sites and always monitored the SQL profiler along the way. I underestimated the changes I did. The system I built and I still made mistakes. After fixing all the bugs, I learnt this time, and replaced the agents website one by one and monitored closely the profiler which my colleagues had set up for me.
After 3 hours downtime and unstable performance, our system was back on again. At the same time, my supervisor was doing the peformance improving implementation as well, he moved all the report from our member sites to replication. I decided to stay at work through the peak time to monitor a bit more closely, and to make sure everything running normally. Our system performed extremely good, no more jams for the night. Our agent servers didn't show anything unsual anymore. The main DB CPU was under 15% for the whole time. Next week, we will have to monitor again. Hopefully everything solved.
It was a long weekend ... going home and looking for my bed ... that was the only things left in my brain when I left work ...